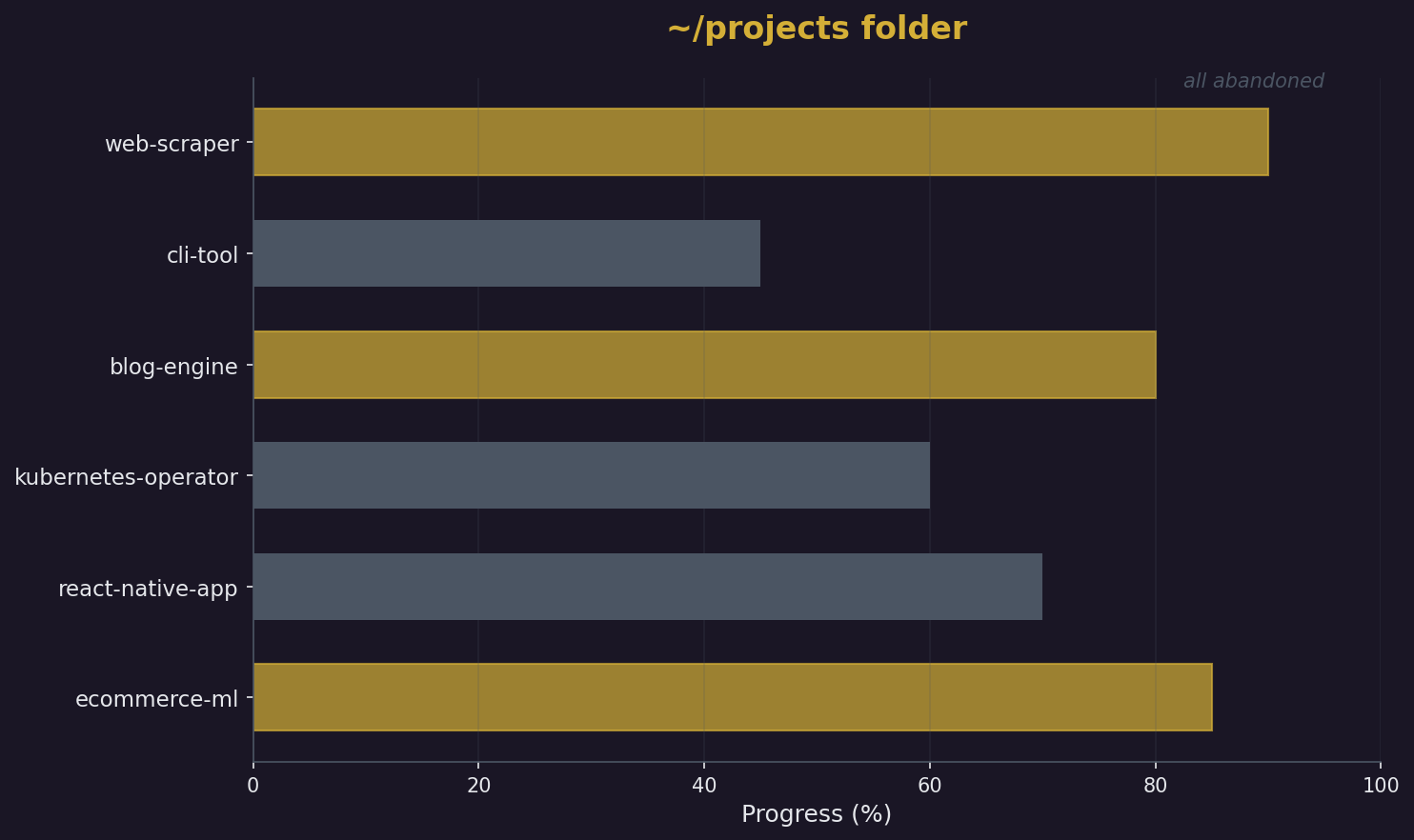
The Project I Didn't Abandon
My laptop has a ~/projects folder. Most of it is a graveyard. Not because the ideas were bad — I’d still build some of them if I sat down today. They’re dead because I get excited by a technical problem, work on it for two weekends, hit the part that stops being fun, and drift to the next thing. The codebase stays. The git log doesn’t. I’m 40, a Cloud Architect with ~18 years across IBM and AWS, and I have ADHD. Diagnosed late, lived with it longer. The pattern above isn’t laziness — it’s a specific shape of attention. Hyperfocus until the dopamine of novelty runs out, then gravitational pull toward whatever’s next. Anyone with this wiring recognizes the feeling: the moment a project transitions from “fun problem” to “ten unsexy decisions in a row,” part of your brain leaves the room. ...