Running Modern LLMs on a 2016 IBM POWER8 in 2026
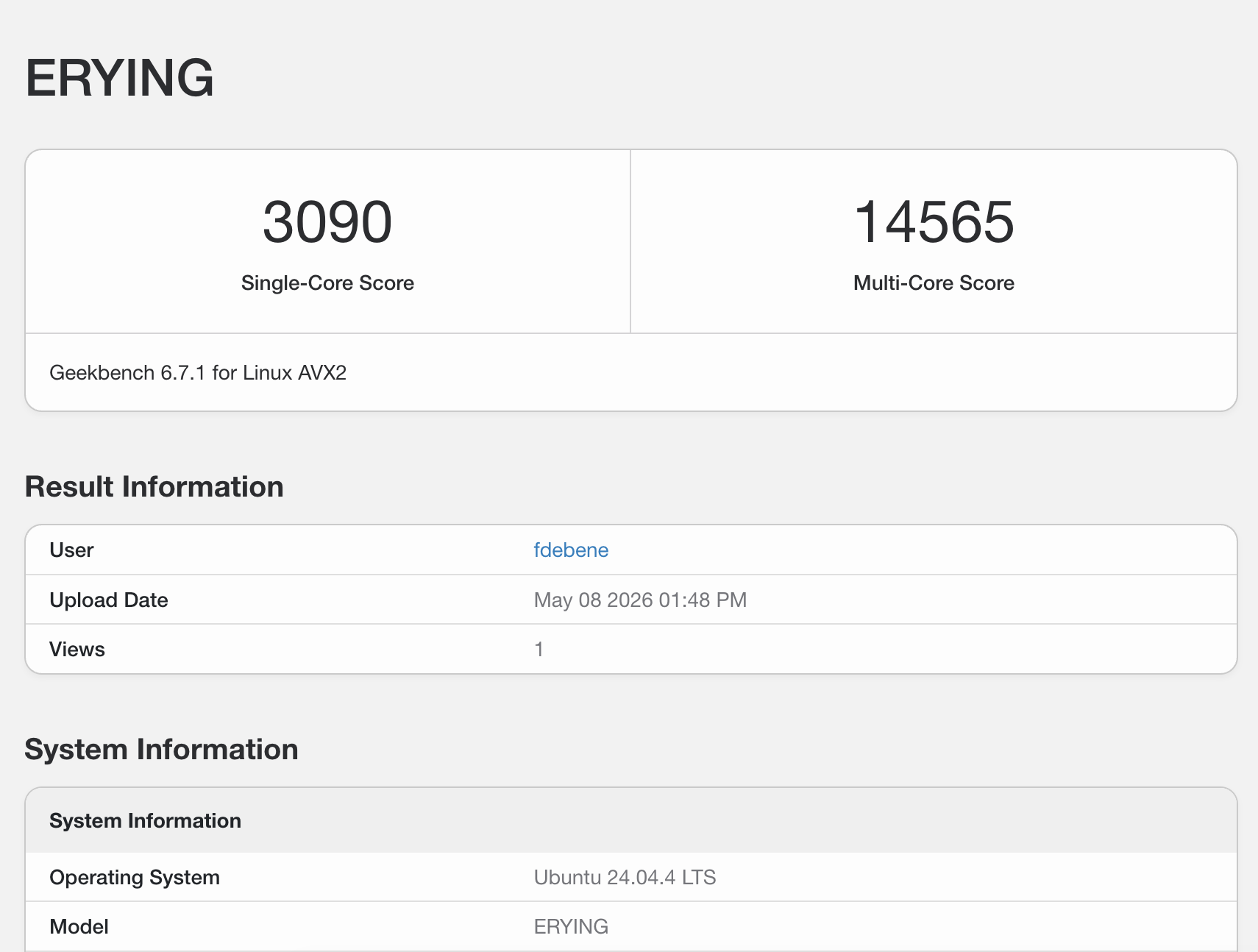
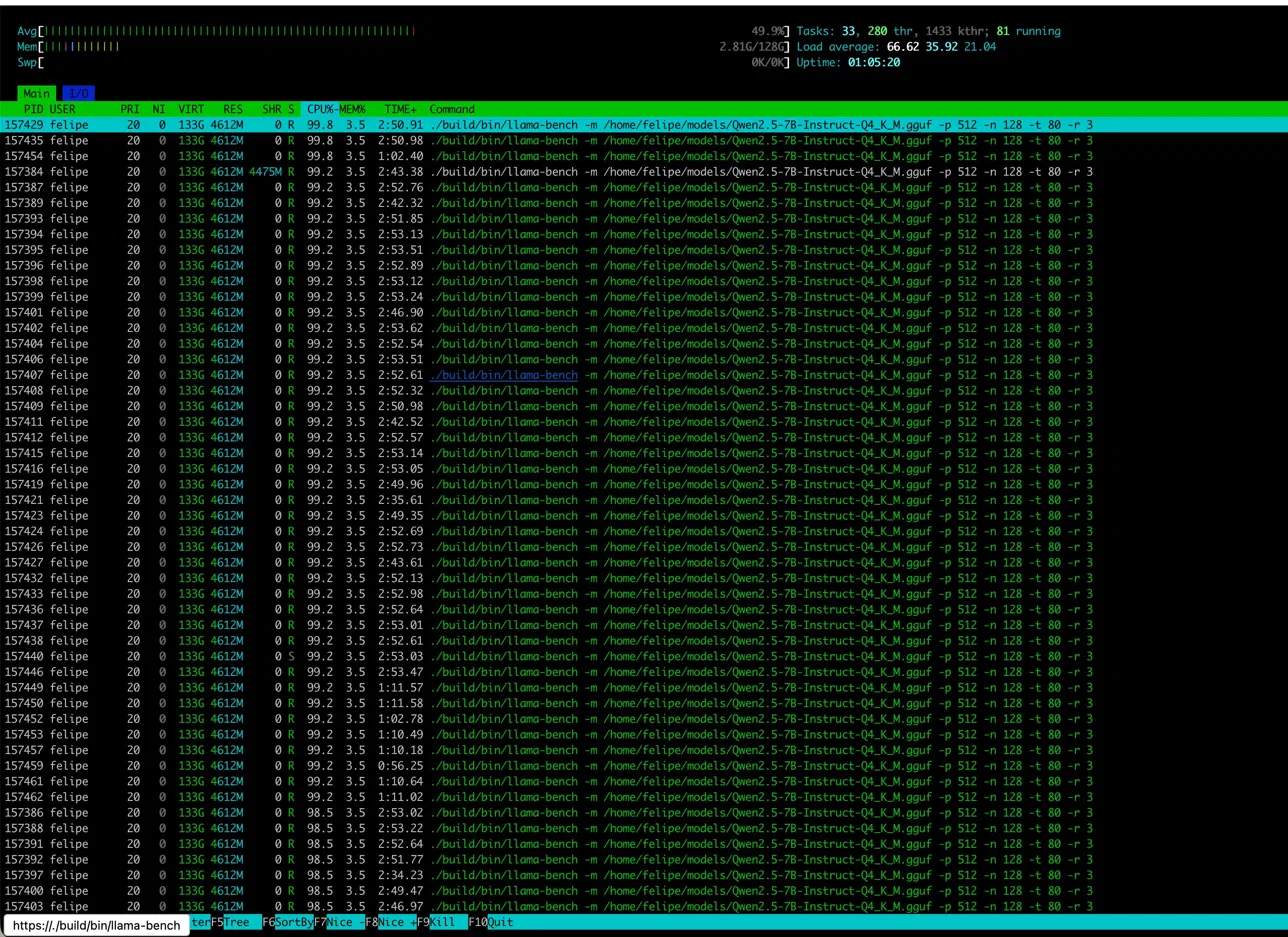
What Are We Even Doing Here? It’s 2026. Most people run LLMs on NVIDIA H100s, AMD MI300X, or at least a decent gaming GPU. I’m running them on a 2016 IBM POWER8 server with 160 hardware threads and zero CUDA cores. Why? Because I can. And because nobody else has published POWER8 LLM benchmarks in 2026. And because alternative architectures deserve love too. This post covers: Building llama.cpp on ppc64le with GCC 16 Running Qwen 2.5 7B (text + vision) on POWER8 NUMA tuning discoveries (spoiler: conventional wisdom is wrong) Multimodal inference (yes, vision models work too) Full reproduceability (Gentoo USE flags, build commands, everything) TL;DR: Got 6.81 tokens/s on text generation and fully functional vision inference. POWER8 reads license plates better than some humans. ...